キーワード辞典
かなり乱暴な構造体の話
登録日 13/05/19 更新日 13/06/18
構造体
関連性の有るデータをひとまとめにして操作出来る様にしたデータ構造。 COBOLの階層的な集団項目に似ているが、 COBOLの場合は定義することで実際に領域が確保されるが、 C言語の構造体の宣言はあくまでも雛形で、構造体名を型として変数を宣言することにより実際に領域が確保されるなど、 違う点も多いので要注意。 物凄く乱暴に言えば、charやintなどの用意されたデータ型を組み合わせて作成出来る オーダーメイドなデータ型。
C言語って、「こういう書き方も出来る」とか「こういう考え方もある」とか、いっぱい有るので、 とりあえず、ざっくりと。
例1:とある11ホームの生徒名簿の例。
seito_meiboが構造体名。
仕様書の様なもので、未だ実体は無い。
seito_meibo構造体を基にして作られた、
seito_meibo構造体型の変数名が meibo_11。
これが実体で、実際にデータが扱われる。
構造体を構成する number や *name といった変数をメンバ変数という。
プログラム中でメンバ変数を指定したい場合は、構造体型の変数名.メンバ変数名、と書く。
構造体の配列も勿論可能。
/* RynStruct.c 2013.5.19 */
#include <stdio.h>
struct seito_meibo{
int number;
char *name;
};
int main()
{
struct seito_meibo meibo_11[2]={{1101,"katou"},{1102,"satou"}};
int i;
for(i=0;i<2;i++){
printf("%d %s¥n ", meibo_11[i].number, meibo_11[i].name);
}
}
構造体の中で配列も使える。
例2:とある11ホームの実力テスト成績表の例。
/* RynStruct2.c 2013.5.19 */
#include <stdio.h>
struct jitsuryoku_test{
int number;
char *name;
int seiseki[3];
};
int main()
{
struct jitsuryoku_test test_11[2]=
{{1101,"katou",{100,100,100}},{1102,"satou",{90,90,90}}};
int i,j;
for(i=0;i<2;i++){
printf("%d %s ", test_11[i].number, test_11[i].name);
for(j=0;j<3;j++){
printf("%3d ", test_11[i].seiseki[j]);
}
printf("¥n");
}
}
構造体の中で既にある構造体を使うことが出来る。
あくまでも雛形を使っているだけでデータは別なので注意。
例3:とある11ホームの実力テスト成績表の例 その2。
/* RynStruct3.c 2013.5.19 */
#include <stdio.h>
struct seito_meibo {
int number;
char *name;
};
struct jitsuryoku_test{
struct seito_meibo meibo;
int seiseki[3];
};
int main()
{
struct jitsuryoku_test test_11[2]=
{{1101,"katou",{100,100,100}},{1102,"satou",{90,90,90}}};
int i,j;
for(i=0;i<2;i++){
printf("%d %s ", test_11[i].meibo.number, test_11[i].meibo.name);
for(j=0;j<3;j++){
printf("%3d ", test_11[i].seiseki[j]);
}
printf("¥n");
}
}
構造体のためのポインタ変数の例。
そもそも、ポインタ変数に1を加えるというのは、
そのポインタ変数のデータ型の大きさの分だけアドレスを移動するということなので、
構造体の配列のポインタ変数に1を加えるというのは、
その構造体の大きさの分だけアドレスを移動する→
COBOLでいう次のレコードに行くという意味合いになる。
うっかりしやすいので注意。
例4:とある11・12ホームの実力テスト成績表の例 その3。
ついでに合計も表示。
/* RynStruct4.c 2013.5.19 */
#include <stdio.h>
void ichiran_hyo(struct jitsuryoku_test *p);
struct jitsuryoku_test{
int number;
char *name;
int seiseki[3];
};
int main()
{
struct jitsuryoku_test test_11[2]=
{{1101,"katou",100,100,100},{1102,"satou",90,90,90}};
struct jitsuryoku_test test_12[2]=
{{1201,"kudou",95,95,95},{1202,"sudou",85,85,85}};
ichiran_hyo(test_11);
ichiran_hyo(test_12);
}
void ichiran_hyo(struct jitsuryoku_test *p)
{
int i,j,kei;
for(i=0; i<2; i++){
printf("%d %7s ",(p+i)->number,(p+i)->name);
kei=0;
for(j=0; j<3; j++){
printf("%3d ", (p+i)->seiseki[j]);
kei+=(p+i)->seiseki[j];
}
printf(" %3d¥n",kei);
}
printf("¥n");
}
構造体を使うとデータのソートもまとめて出来る。
例5:とある漢字テストの順位表の例。得点順、得点が同じなら文字コード順に並べ替えている。
/* RynStruct5.c 2013.6.18 */
#include <stdio.h>
#include <string.h>
#define NINZU 9
struct Kanji_test{
int bango;
char *name;
int tokuten;
};
void swap(struct Kanji_test *i, struct Kanji_test *j);
int main(){
struct Kanji_test jukensya[]={
{2101,"あとう", 90},{2102,"かとう", 85},{2103,"さとう", 95},
{2201,"うどう" ,100},{2202,"くどう", 65},{2203,"すどう", 70},
{2301,"えんどう",85},{2302,"せんどう",80},{2303,"てんどう",75}};
int i,j,k;
printf("¥n[before]¥n");
for(k=0; k < NINZU; k++){
printf("%d %-8s %3d¥n", jukensya[k].bango, jukensya[k].name, jukensya[k].tokuten);
}
for(i=0; i < NINZU-1; i++){
for(j=i+1; j < NINZU; j++){
if(jukensya[i].tokuten < jukensya[j].tokuten)
swap(&jukensya[i], &jukensya[j]);
else if((jukensya[i].tokuten == jukensya[j].tokuten)&&
(strcmp(jukensya[i].name, jukensya[j].name) > 0))
swap(&jukensya[i], &jukensya[j]);
}
}
printf("¥n[after]¥n");
for(k=0; k < NINZU; k++){
printf("%d %-8s %3d¥n", jukensya[k].bango, jukensya[k].name, jukensya[k].tokuten);
}
}
void swap(struct Kanji_test *i, struct Kanji_test *j)
{
struct Kanji_test work;
work = *i;
*i = *j;
*j = work;
}
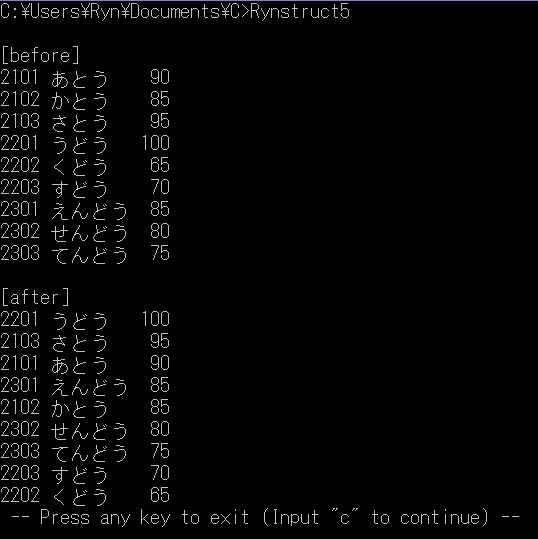 実行結果
実行結果
![[ 赤い玉の画像 ]](../Gif/RedBall.gif)
![[ 黒板消しとチョーク受けの画像 ]](../Gif/BlackBoardEnd.gif)