キーワード辞典
関係データベースの第1正規化が本によって違うワケ
登録日 08/12/05 更新日 12/01/08
※面倒臭いので「関係」と書いていますが、
適宜「リレーショナル」「リレーション」などと読み替えていただけると幸いです。
下図も参考にして下さい。
前提1
そもそも、関係DBってのは関係によるデータの集合(←数学の)で、
それを表の形に例えて、テーブルだとかフィールドだとかレコードだとか名前を付けて、
概念として判り易い様にしている。
個人的には、単純なものとしてトランプの七並べを想像していただけると良いのかも、と思う
(肝心のデータが無いけど、その時はカードにマジックで何か書いて下さい)。

トランプのカード。
普段は1枚1枚がバラバラになっているが、並べるとこんな感じになる。
なので、元々関係DB自体には、表計算ソフトの様な
保存される状態でのレコードの順序やフィールドの順序というものは存在しない。
また、関係DBの関係(例えがズルいけど表計算ソフトでいえば1つのセルの値同士の参照)は、
スカラ値でなければならないことになっている。
スカラ値というのは「データとしてそれ以上分割出来ない値」のことで、
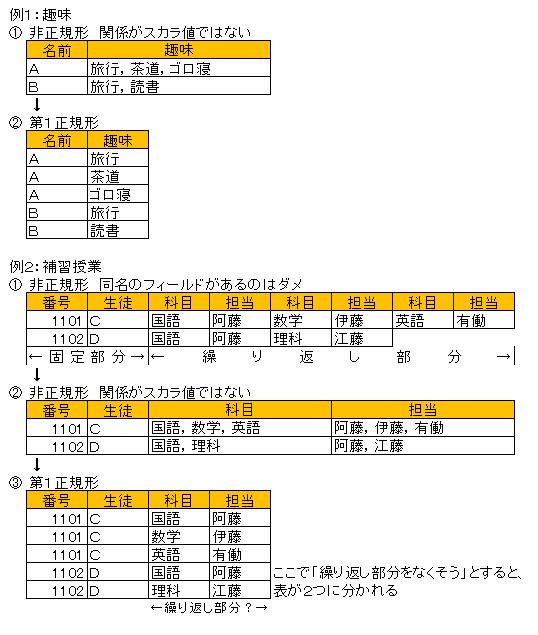
例えば、「趣味」というフィールドに「旅行,茶道,ゴロ寝」という値が有る場合、
これはスカラ値ではない、という(データの意味にもよるけど)。
要はKJ法で言う「一つの付箋紙には一つの事だけ」と同じ発想。
データ同士を関係付けていく上で幾つもの分割出来る値が有ったのでは関係DBとして意味が無いので、
これは当然の事である。
前提2
関係DBにおける第1正規化の定義は、「関係がスカラ値のみで有ること」である。 少なくとも、Wikipediaをはじめ、大抵の専門的なWebPageには、そう書かれている。
以上を踏まえて
非正規形を図式するやり方は幾つか有るが、
例えば、非正規形を、1つの固定部分の後に繰り返し部分が何度も繰り返されて1レコードになっている状態とみなした場合、
1レコードに同じフィールドが何度も現れることになり、
それはフィールド側から見れば、前提1より、そのフィールドには複数の値が存在する、
スカラ値では無い状態となる。
繰り返し部分のフィールドに例えば1とか2とか番号を付ければ、
と考えるかもしれないが、それではお互いが別のフィールドのデータということになり、
管理が複雑になり関係DBとして無意味になる。
これを解消するのが第1正規化であり、
第1正規化された形が、例えば、実教出版の平成23年度版全商情報処理検定模擬問題集1級(*1)の正規化の説明の表になる。
勿論、第1正規形のままでは無駄が多いし更新時の不都合なども起きるので、さらに第2以降の正規化を行なう。
...と、私自身は考えている人間ですが、
問題集や参考書によっては色々な解釈で書いてあって、教える側としては、とても面倒臭い。
まぁ、正規化の本来の目的は、
関係DBには選択や射影や結合という便利な機能が有って、
データをどうにでも関係出来るのだから、それなら、同じデータを複数持つのは無駄だし変更も面倒だから無くしましょ、
ということなので、過程の処理が正しく出来ていればそれが第1という名前でも第2という名前でも、
そんなのは実務としては殆どどうでも良いことだし、
「スカラ値にする」→「繰り返しをなくす」→「繰り返し部分をなくす」という言葉の微妙なニュアンスから、
第1正規化で2つの表に分けてしまえ、という解釈が生まれたのだろうな、たぶん。
定義としては「関係がスカラ値」であれば他はどうでもそれは第1正規形なので
(第2正規形は第1正規形を包含し、第3正規形は第2正規形を包含する)、
どっちが誤りかなんて一概には言えないのだろうけれど、
でも、特に、情報処理技術者試験の上位級を目指す方は注意した方が良いらしいです(伝聞)。
*1
偶々目の前に有ったのがこの本で、大抵の商業高校には有るかなと思うから書いただけで、特に意図は無い、念のため。
![[ 赤い玉の画像 ]](../Gif/RedBall.gif)
![[ 黒板消しとチョーク受けの画像 ]](../Gif/BlackBoardEnd.gif)