キーワード辞典
データ圧縮
登録日 08/12/05 更新日 08/12/05
その1(ランレングス符号の一例)
同じものが続く場合に、データそのものではなく、何が幾つ続くかを数字であらわすことでデータ量を減らす。
簡単な例として、文字単位で、「*」を「繰り返す回数を示す数の目印」と規定すると、
すもももももももももももももいろいろ
というデータは、
すも*13いろいろ
となる。
連続するデータには有効だが、連続しないデータでは増えてしまう場合もある。
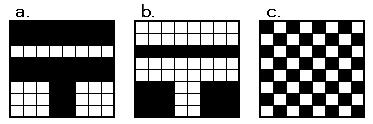 白黒のファックスの様に、2つの値が交互にあらわれると判っている場合は、何が、の部分が要らなくなるため、
データを少なくする事が出来る。
例えば、黒から始まり、左上から右横へ順に、とルールを決めておくと、
右図のaの場合は、
白黒のファックスの様に、2つの値が交互にあらわれると判っている場合は、何が、の部分が要らなくなるため、
データを少なくする事が出来る。
例えば、黒から始まり、左上から右横へ順に、とルールを決めておくと、
右図のaの場合は、
16.8.16.3.2.6.2.6.2.3
と、なり、
bの場合は、白から始まっているために、最初は黒が0ということにして、
0.16.8.16.3.2.6.2.6.2.3
と、なる。
cの市松模様の様に連続しない場合は、効果がない。
その2
同じパターンが繰り返しあらわれる場合に、
前に出たパターンの相対的な開始位置とパターンの範囲を数字であらわすことでデータ量を減らす。
簡単な例として、文字単位で、「*」を「パターンの位置を示す数字の目印」と規定すると、例えば、
だれかさんとだれかさんがむぎばたけ
というデータは、7~11文字目「だれかさん」が6文字前から5文字分と同じなので、
だれかさんと*65がむぎばたけ
となり、同様に、
きしゃきしゃぽっぽぽっぽしゅっぽしゅっぽしゅっぽっぽ
というデータは、
きしゃ*33ぽっぽ*33しゅっぽ*44*44*22
となる。
その3
その2の変形。
同じパターンが繰り返しあらわれる場合に、
パターンを辞書に登録し、対応する記号を使用することでデータ量を減らす。
簡単な例として、文字単位で、「*」を「登録されたパターンの記号を示す目印」と規定すると、例えば、
きしゃきしゃぽっぽぽっぽしゅっぽしゅっぽしゅっぽっぽ
で、「きしゃ」をK、「ぽっぽ」をP、「しゅっぽ」をS、と辞書に登録していくと、
*K*K*P*P*S*S*Sっぽ
と変換する事が出来る。
その4(ハフマン符号の一例)
ハフマン符号は、1952年にデビット・ハフマン(David Huffman)によって考案された符号。
出現頻度によって文字コードのビット数を変えることでデータ量を減らす。
出現頻度が大きければビット数を少なく、小さければビット数を多くする。
簡単な例として、文字単位で、例えば、
きしゃきしゃぽっぽぽっぽしゅっぽしゅっぽしゅっぽっぽ
というデータを変換したい場合、
1.各文字の出現頻度を求める。
2.必要に応じて出現頻度で大きい順に並べ替える。
3.頻度の下位2つを二分木の子にしてつなぎ、親の出現頻度を2つの和にする。
下位2つがaとbの場合、(ab)と書くことにする。
4.2へ戻って繰り返す。
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
ぽ 8回 っ 6回 し 5回 ゅ 3回 き 2回 ゃ 2回 |
ぽ 8回 っ 6回 し 5回 (きゃ) 4回 ゅ 3回 |
ぽ 8回 ((きゃ)ゅ) 7回 っ 6回 し 5回 |
(っし) 11回 ぽ 8回 ((きゃ)ゅ) 7回 |
(ぽ((きゃ)ゅ)) 15回 (っし) 11回 |
((ぽ((きゃ)ゅ))(っし)) 26回 |
5.全ての文字が二分木につながったところで、根から、右向きなら1、左向きなら0、のビットを割り振っていく(逆でも良い)。
カッコを補足して書くと、
【 { ぽ } { [ ( き )( ゃ ) ] [ ゅ ] } 】【 { っ }{ し } 】
1ビット目は【 】、2ビット目は{ }、3ビット目は[ ]、4ビット目は( )、と、外側のカッコのペアから、
右側にあれば1、左側にあれば0、と、たどっていくと、
ぽ 00 き 0100 ゃ 0101 ゅ 011 っ 10 し 11
![[ 赤い玉の画像 ]](../Gif/RedBall.gif)
![[ 黒板消しとチョーク受けの画像 ]](../Gif/BlackBoardEnd.gif)